Team Members
Esha Uboweja, Bojian Han
Final Report
Project Update
In our project, we implemented a parallel RNN that trains using backpropagation through time (BPTT) in Halide and benchmarked our Halide implementation against our implementation of Theano RNN and NumPy RNN which are highly optimized for the task.
We have made algorithmic improvements to the backpropagation algorithm shown in the (WildML tutorial) which has an O(N^2) algorithm to implement BPTT, w.r.t. The number of input, hidden and output nodes in the RNN. Our version uses an O(N) algorithm for BPTT and this runs much faster. We have also implemented an RNN in NumPy which produces numerically equivalent updates and results as the original Theano RNN implementation, with some variation in floating point accuracy. Our NumPy implementation achieved over 2x speedup for small inputs and is slightly faster than Theano for larger inputs.
In Halide, we have utilized parallelism and scheduling techniques that we learnt in the first 3 assignments of the class as well as techniques for matrix multiplication and inspirations from Spark RDD lecture. This is demonstrated via vectorization of code using Halide scheduling optimizations, parallelization using multiple threads using the Halide scheduler, tiling for matrix operations, loop fusing via both of Halide JIT and Halide AOT pipelines, as well as manual loop fusing. Additionally, we have also explored the usage of AOT to remove the excessive compilation time due to JIT for functions that are repeatedly compiled and reused.
Our current Halide implementation scales well for large inputs, runs only at 50% of the speed of Numpy version for large inputs of 1024 by 1024 images. Take note however that this is a HUGE improvement from same Halide code without the optimizations we described above, as the naive serial Halide implementation is almost 100~300 times slower than the NumPy version. For example, 1 epoch of training the RNN takes 366 seconds in the naive Halide implementation, 8 seconds in our optimized Halide implementation and 5 seconds in our NumPy implementation.
Project Checkpoint
Needs attention
We need the following setup on "latedays" machines so that we can test our implementation on the Xeon Phi:
- Theano for Python
- Halide (requires a new LLVM version)
Progress
We have code for training RNNs using Theano and Python with Numpy.
We have a better understanding of the Backpropagation Through Time (BPTT) for RNNs, and how some parts of it can depend on our choice of the non-linear activation. Our Python code presently uses
tanh, a popular set of choices is [tanh,sigmoid,ReLU].We have gone through Halide tutorials and have decided to code our RNN implementation using Halide. We decided this because of the efficiency of matrix operations in Halide. Another reason is that while we can use OpenBLAS or similar BLAS libraries in C++ for efficient matrix algebra, we don't have to reimplement our RNN if we want to test it on GPU.
Evaluation Plan
We will compare our parallel RNN implementation speedup against a Theano implementation. We are familiar with Theano and we know Theano compiles optimized code for different platforms. Our implementation will be benchmarked against similar performance in Theano with the exact same network structure (this means that if our network does not use bias, the Theano one will not use bias either). When our implementation uses mini-batch data-parallelism for training the network, the Theano implementation will use mini-batch training using Matrix-Matrix multiplication (Weights Matrices and Batches of Training Vectors concatenated into a matrix) and Theano's API for calculating gradients.
-
It is a fact that simple, 1 hidden layer RNNs are not widely used at this time because of more interesting networks like multi-layer RNNs and LSTMs. This implies a difficulty in finding good problems and datasets to test our implementation. However, our goal is to parallelize and efficiently train a 1 hidden layer RNN. We therefore have come up with 2 types of problems for testing our RNNs:
i. Learning simple convolutional filters - RNNs are designed to learn about temporal dependencies for a given data sequence of values at different time-steps. We can treat images as sequences of pixels, so that a row of pixels
[0 0 100 200]can be thought of as a sequence of pixels observed at time-steps0,1,2,3. This is similar to "walking" along the columns of an image from left to right. Treating images in this manner allows us to learn simple filters like a 1D Sobel filter[-1 0 1]for example (we have code in Theano for this). Further, data generation and scalability work into this problem well, because we can simply generate a lot of images or use a popular dataset like MNIST, and train and test our implementation.ii. Dealing with image sequences, videos - We can setup an RNN to generate sequences of spatial differences between frames. Problem setup:
- Input to the RNN model: A sequence of consecutive frames
- Output of the RNN model: A sequence of temporal differences between frame at time t-1 and time t
- Size of dataset: Unlimited since we can generate dataset from lots of images by applying transformations to it/Or we can get videos and train on these videos
- Size of input/output: Depends on size of images which can vary
- Final evaluation in terms of functionalities: This RNN model can be easily trained for small inputs. However, it is uncertain if the RNN can learn well for large images because the network might not be able to find the correct optima when the input is too large because the layers are fully connected. In order to evaluate this, we may need to check size of images from small (20x20) to large (200x200).
- Final evaluation in terms of parallelism testing: Since our project is primarily focused on using Halide to schedule the RNN computation, it is important to test the scheduling against multiple parameters to identify the various machine factors involved such as caching, RAM or even disk memory access speed as input increases.
We aim to present graphs showing performance and speed up on these two applications compared to a baseline implementation in Theano, and various scheduled implementations in Halide, on a multi-core CPU. Since we have chosen some interesting image based problems, we will also try to visualize results obtained by testing the RNN v/s expected output where possible.
Revised Schedule
- April 20 - April 23
- Implement and test a "serial" RNN in Halide on Application 1 (Esha)
- Explore 3D matrix operations and their optimizations in Halide (Bojian)
- April 26 - April 30
- Test "serial" RNN on Application 2 (Esha)
- Work with different scheduling algorithms and cache level optimizations for data-parallel RNNs (Esha + Bojian)
- April 30 - May 6:
- Finalize benchmarks on Applications 1 and 2 (Esha + Bojian)
- Work on report (Esha + Bojian)
- Use this time to possibly do a 3rd application (either text/video based)
- May 6 - May 9: Work on presentation (Esha + Bojian)
Project Proposal
Team Members
Esha Uboweja, Bojian Han
Summary
We are going to implement a fast, parallel version of Recurrent Neural Networks (RNNs). We will optimize RNN training performance on multi-core CPUs.
Background
RNNs are neural networks that make use of memory to store certain pieces of information, so that outputs at a time-step t are dependent on inputs at time-step t, as well as inputs at time-steps t-1, t-2, etc. While the duration of this "memory" is short, i.e. output at t is dependent only up to T steps back in time, such recurrent dependency pattern requires the network to be iterative in at least 2 ways. Firstly, as in many neural networks, an epoch of training can happen only after a previous epoch of training is completely. This iterative dependency is most likely unavoidable. Further, training the RNN's hidden units for each time-step happens iteratively, so that the update to the hidden unit at time t depends on the update to the hidden unit at time (t-1). This is the core idea implemented as "Back-propagation Through Time" or BPTT for RNNs.
Figure 1: An RNN architecture
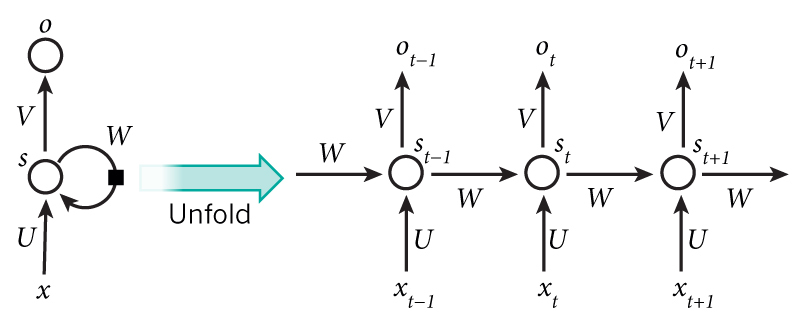
An example of an RNN architecture is shown in Figure 1 (from (1)). As described in (1), the network is described as follows:
- For a given input x, hidden unit set s, the output unit set is o. U, V and W represent the weight matrices for weights from input to hidden units, hidden units to output units and hidden to hidden units respectively.
- We "unroll" the RNN to better understand its representation over time. Note that the weight matrices for each connection type are the same for each input, hidden and output units triplet.
- xt is the input at time-step t, st is the hidden unit at time-step t, ot is the output at time-step t
- st = f(Uxt + Wst-1) where f is a non-linear function such as tanh or the sigmoid function.
- ot = softmax(Vst)
- Note that even though in this figure the number of outputs is equal to the number of inputs, in general this may not be the case.
Challenges
- As discussed in the Background section, there are a lot of iterative dependencies in RNN, which makes it challenging to implement them in parallel
- Further, for different hidden units, there may be different amounts of work because a hidden unit at time-step t has to iteratively use the computation of the hidden unit at time-step (t-1), and so on.
- On CPUs, an interesting problem happens when the training data for 1 epoch is too large to fit in cache. Training many epochs iteratively in such a case will be slow, and a speed-up is highly desired for this simple issue as well.
- The activation functions such as sigmoid and tanh are non-linear, so the hidden unit computations are non-linear as well. This makes the problem of parallelizing the hidden unit updates even more challenging.
A fast parallel implementation of RNN should use training data of arbitrary sizes efficiently and also try to optimize over dependencies of the gradient descent updates to the 3 weight matrices for multiple hidden units.
We believe one way to solve this problem is to implement a data-parallel RNN training scheme, that batches up sets of data (or the entire set of data) and feeds it directly to the network for training. We are also investing some other approaches, such as those described in (2).
Goals/Deliverables
-
Plan:
- Successfully implement a fast, parallel implementation of RNN on multi-core CPUs, using one of OpenMP, ISPC and Halide.
- Present results and benchmarks on our parallel RNN framework's correctness and speed as compared to a sequential version on a few datasets (either language based or image based).
-
Hope:
- Implement a parallel RNN framework in more than one of Halide, ISPC or OpenMP and compare and analyze these implementations.
Resources
We will write code in C++ (or perhaps Halide). C++ is our first choice because we have used it throughout the semester for class assignments and we know our code doesn't require any additional setup on gates machines or on the "latedays" machine cluster. We are new to using Halide, which is a Domain Specific Language (DSL) for image processing. In Halide, the matrix computations could be faster, but we will finalize our choice of language in our first project week.
We are programming a CPU-based implementation because while GPUs are very common, a multi-core CPU is a more common platform, and perhaps even cheaper. If time permits, we may look into a GPU based implementation (and modify our "Hope to achieve" set of goals!).
Schedule
- April 02 - April 08: Implement serial RNN from scratch in C++
- April 09 - April 15: Implement a parallel RNN in C++
- April 16 - April 22: Train RNN on some small datasets AND parameter tuning for parallel RNN implementation
- April 23 - April 29: Implement clever data decomposition and training schemes for large datasets
- April 30 - May 6: Finalize implementation + benchmarking AND report
- May 6 - May 9: Work on presentation